Na vrhuncu ustvarjanja STL in nasilne vojne standardnega jezika C ++ so številni programerji razvili lastno knjižnico različnih platform, ki razvijalcem zagotavlja orodja za reševanje vsakodnevnih nalog, kot so obdelava podatkov, algoritmi, manipulacija datotek itd. . Projekt je tako uspešen, da so zmogljivosti podjetja Boost sposojene in se prilegajo standardnemu jeziku, začenši s C ++ 11. Ena od takih aplikacij je izboljšano delo z naključnimi številkami.


Generator psevdorandnih številk

# vključi
int roll_a_dice () {
std :: default_random_engine e {}; //ustvarite naključni generator
std :: uniform_int_distribution
vrnitev d (e);
}
Tipična napaka tistih, ki preučujejo naključno, je ignorirati ustvarjanje porazdelitve in prehod takoj na ustvarjanje naključnih števil na način, na katerega so navajeni. Poglejmo na primer to funkcijo.
vrnitev 1 + e ()% 6;Nekateri menijo, da je njegova uporaba dovoljena. Ker vam C ++ to omogoča. Toda ustvarjalcem knjižnice Boost in C ++ 11 priporočamo, da tega ne storite. V najboljšem primeru bo to preprosto slaba koda, in v najslabšem primeru bo to tekalna koda, ki naredi napake, ki jih je zelo težko ujeti. Uporaba distribucij zagotavlja, da programer prejme tisto, kar se pričakuje.
Inicializacija generatorja in semena
Stopnja napovedi, opredelitve in ustvarjanja entitet se pogosto obravnava kot nekaj, kar ni vredno posebne pozornosti. Toda premalo premišljena inicializacija generatorja naključnih števil lahko vpliva na njeno pravilno delo.
std :: default_random_engine e1; //implicitna inicializacija na privzeto vrednost
std :: default_random_engine e2 {}; //privzeta privzeta privzeta vrednostPrvi dve inicializaciji sta enakovredni. In večinoma se nanašajo na okus ali standarde pisanja dobre kode. Toda naslednja inicializacija je korenito drugačna.
& lt; script type = "text /javascript" & gt;
lahko blockSettings2 = {blockId: "R-A-70350-2", renderTo: "yandex_rtb_R-A-70350-2", async:! 0};
če (document.cookie.indexOf ("abmatch ="))> = 0) {
blockSettings2 = {blockId: "RA-70350-2", renderTo: "yandex_rtb_R-A-70350- 2 ", statId: 70350async: 0};
}
Funkcija (a, b, c, d, e) {a [c] = a [c] || [], a [c] .push (funkcija () {Ya .Context.AdvManager.render (blockSettings2)}), e = b.getElementsByTagName ("script") , d = b.createElement ("script"), d.type = "text /javascript", d.src = "//an.yandex.ru/system/context.js", d.async =! 0e.parentNode.insertBefore (d, e)} (to, ta.dokument, "yandexContextAsyncCallbacks");
std :: default_random_engine e3 {31255}; //inicializirati na 31255"31255" - to se imenuje seme (seme, izvor) - število, na podlagi katerega generator ustvari naključne številke. Ključna točka pri tem je, da mora biti s takšno inicializacijo vrsta semen enaka ali se nanaša na tip, s katerim deluje generator. Ta tip je na voljo prek elementa decltype (e ()) ali result_of ali typename.
Zakaj generator ustvari enaka zaporedja?
Če se program zažene večkrat, generator vedno ustvari enako zaporedje števil, če se njegova inicializacija ne spremeni, to pomeni, da je definicija generatorja enaka od zagona do zagona programa. Po eni strani je takšno samo-reproduciranje števil s strani generatorja koristno, na primer, pri razhroščevanju. Po drugi strani pa je nezaželena in lahko povzroča težave.
Skladno s tem, da bi se izognili ponavljanju zaporedja števil, mora generator pri vsakem zagonu programa inicializirati različne vrednosti. Samo za te namene lahko uporabite seme. Standardni način inicializacije DWR je, da mu pošljemo semensko vrednost časa
datoteke ctime glave. To pomeni, da se generator inicializira z vrednostjoenako številu sekund od januarja 1 00 ure 00 minut 00 sekund, 1970 UTC.
Inicializacija DVR s strani drugega generatorja
Čas za inicializacijo morda ne bo dovolj za reševanje številnih težav. Nato lahko definirate DVR prek drugega generatorja. Tukaj bi rad naredil umik in govoril o enem zmogljivem orodju, ki vam omogoča, da ustvarite resnično naključne številke.
Random_device - Generator resničnih naključnih številk

Vsi generatorji psevdorno naključnih števil so deterministični. To pomeni, da imajo definicijo. Z drugimi besedami, generiranje naključnih števil temelji na matematičnih algoritmih. Random_device je nedeterminističen. Ustvari številke, ki temeljijo na stohastičnih (naključnih iz drugih grških) procesov. Takšni procesi so lahko spremembe faze ali amplitude trenutnih nihanj, nihanja molekulskih mrež, gibanje zračnih mas v ozračju itd.
& lt; script type = "text /javascript" & gt;
lahko blockSettings3 = {blockId: "R-A-70350-3", renderTo: "yandex_rtb_R-A-70350-3", async:! 0};
if (document.cookie.indexOf ("abmatch ="))> = 0) {
blockSettings3 = {blockId: "RA-70350-3", renderTo: "yandex_rtb_R-A-70350- 3 ", statId: 70350async: 0};
}
Funkcija (a, b, c, d, e) {a [c] = a [c] || [], a [c] .push (funkcija () {Ya .Context.AdvManager.render (blockSettings3)}), e = b.getElementsByTagName ("script") , d = b.createElement ("script"), d.type = "text /javascript", d.src = "//an.yandex.ru/system/context.js", d.async =! 0e.parentNode.insertBefore (d, e)} (to, ta.dokument, "yandexContextAsyncCallbacks");
Očitno ni mogoče vgraditi vsakega računalnika in ne vsakega sistema v možnost pridobitve naključnega števila na podlagi stohastičnega procesa. Zato je uporaba random_device smiselna le, če je to potrebno. Njegovo delo lahkorazlikujejo od sistema do sistema, od računalnika do računalnika, in morda je popolnoma izven dosega. Zato je pri uporabi resničnega generatorja naključnih številk potrebno zagotoviti ravnanje z napakami.
Uporaba random_device kot semena za DSPF
std :: random_device rd {};
std :: default_random_engine e {rd ()};
V tem kodeksu ni nič bistveno novega. Hkrati se z vsakim zagonom DIRF inicializira z naključnimi vrednostmi, ki jih generira pravi generator naključnih števil rd.
Prav tako je treba omeniti, da se lahko vrednost inicializacije generatorja kadar koli ponastavi:
e. Seed (15027); //inicializiramo s številko
e.seed (); //inicializira se na privzeto vrednost
e.seed (rd ()); //Inicializacija z drugim generatorjem
Povzetek: generatorji in porazdelitve
Generator (motor) je objekt, ki omogoča ustvarjanje različnih številk verjetnosti.
Distirbution je objekt, ki pretvori zaporedje števil, ki jih generira generator, v porazdelitev po določenem zakonu, na primer:
- enotna (enotna);
- normalna - Gaussova porazdelitev (normalna);
- binom (binom) itd.
Razmislite o generatorjih standardne knjižnice C ++.
- Dovolj je, da novinci uporabljajo default_random_engine, pri čemer izbiro generatorja pusti v knjižnici. Generator bo izbran na podlagi kombinacije dejavnikov, kot so zmogljivost, velikost, kakovost naključja.
- Knjižnica za napredne uporabnike ponuja 9 predhodno konfiguriranih generatorjev. So zelo različniproduktivnost in velikost, hkrati pa je bila njihova kakovost dela izpostavljena resnim testom. Pogosto se uporablja oscilator, imenovan Mersenne twister motorji in njegov primer mt19937 (ustvarjanje 32-bitnih številk) in mt19937_64 (ustvarjanje 64-bitnih števil). Generator je optimalna kombinacija hitrosti in stopnje naključnosti. Za večino izzivov bo dovolj.
- Za strokovnjake knjižnica zagotavlja nastavljene predloge za generatorje, ki omogočajo ustvarjanje dodatnih vrst generatorjev.
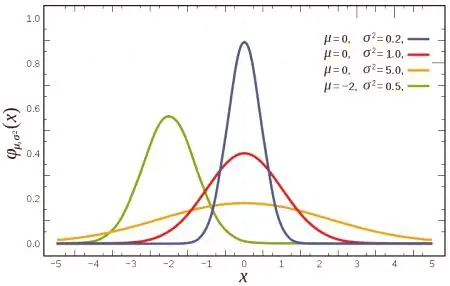
Upoštevajte ključne vidike distribucij. V standardnem jeziku je 20 kosov. V zgornjem primeru je bila uporabljena enakomerna porazdelitev naključne knjižnice C ++ v območju [a, b] za cela števila uniform_int_distribution. Ta distribucija se lahko uporabi za realna števila: uniform_real_distribution z enakimi parametri a in b kot generiranje števil. Hkrati so vključene meje vrzeli, tj. [A, b]. Seznam vseh 20 distribucij in ponovite C ++ dokumentacijo v članku nima smisla.
Opozoriti je treba, da vsaka porazdelitev ustreza njenemu nizu parametrov. Za enakomerno porazdelitev je to interval od a do b. Za geometrični (geometrični) porazdelitveni parameter obstaja verjetnost uspeha str.
Večina distribucij je definirana kot predlogo razreda, za katero je parameter vrsta zaporednih vrednosti. Vendar pa nekatere distribucije ustvarjajo sekvence samo int vrednosti ali samo realno vrednost. Ali, na primer, Bernoullijevo zaporedje (bernoulli_distribution) daje vrednost tipa bool. Kot pri MHF lahko uporabnik knjižniceustvarite lastno distribucijo in jo uporabite z vgrajenimi generatorji ali generatorji, ki bodo ustvarili.
V tej funkciji knjižnice niso omejene. So veliko širše. Informacije, ki so na voljo, pa zadostujejo za uporabo in osnovno razumevanje generatorja naključnih števil v C ++. . Poglejmo primer generiranja naključnega števila C ++ /CLI.
Za tiste, ki delajo v Visual studiu in ne razumejo, zakaj imenski prostor sistema ni definiran.
Za delo .net je potrebno povezati CLR. To je narejeno na dva načina: 1) Ustvarjanje projekta ni konzolna aplikacija za Windows, ampak z CLR - CLR aplikacije (CLR Console Application). storitev ») - & gt; konfiguracija - & gt; splošno - & gt; privzeta vrednost - & gt; v spustnem meniju "Podpora za splošno izvajalno okolje (CLR)" izberite "Podpora okolja CLR (/clr)".
# vključuje "stdafx.h"
# vključi
//uporablja imenski sistem;
int main (polje ^ args)
{
System :: Random ^ rnd1 = gcnew System :: Random (); //ustvarimo MHF, privzeto ga inicializiramo s trenutnim časom
std :: cout rnd1- & gt; Next () "n"; //vrne pozitivno celo število
int zgornje = 50;
std :: cout rnd1- & gt; naslednji (zgornji) "n"; //vrne pozitivno celo število, ki ni večje od zgornjega
int a = -1000; int b = -500;
std :: cout rnd1- & gt; Naprej (a, b) "n"; //vrne celo število v območju [a, b]
int seme = 13977;
Sistem :: Naključno ^ rnd2 = gcnew Sistem :: Naključno (seme); //inicializira MHFštevilo semen
std :: cout rnd2- & gt; Naprej (5001000) n; //se pri vsakem zagonu programa ustvari isto število.
std :: cout std :: endl;
vrnitev 0;
}
V tem primeru se vse delo opravi s funkcijo Random Next C ++ /CLI.
Treba je omeniti, da je .net velika knjižnica z velikimi zmogljivostmi in uporablja lastno različico jezika, imenovano C ++ /CLI iz infrastrukture skupnega jezika. Na splošno je to razširitev C + + na platformo .Net.
Na koncu bomo razmislili o nekaj primerih, da bi bolje razumeli delo z naključnimi številkami.# vključiti
# vključiti
# vključiti
int main () {
std :: mt19937 e1;
e1.seed (čas
);
std :: cout e1 () std :: endl;
std :: mt19937 e2 (čas );
std :: mt19937 e3 {};
std :: uniform_int_distribution
std :: cout uid1 (e2) "," uid2 (e3) std :: endl;
std :: default_random_engine e4 {};
std :: uniform_real_distribution
std :: normal_distribution
std :: cout urd (e4) "," nd (e4) std :: endl;
std :: cout std :: endl;
sistem ("pavza");
vrnitev 0;
}
Sklep
Vse tehnologije in metode se nenehno razvijajo in izpopolnjujejo. To se je zgodilo tudi z mehanizmom generiranja naključnih števil rand (), ki je zastarel in ne izpolnjuje več sodobnih zahtev. V STL obstaja naključna knjižnica, v .Net Framework - Random razred za delo s naključnimi številkami. Uporaba randa bi morala zavrniti prednosti novih metod, saj ustrezajo sodobnim programskim paradigmam, stare metode pa bodo izključene iz standarda.
std :: cout e1 () std :: endl;
std :: mt19937 e2 (čas
);
std :: mt19937 e3 {};
std :: uniform_int_distribution
std :: cout uid1 (e2) "," uid2 (e3) std :: endl;
std :: default_random_engine e4 {};
std :: uniform_real_distribution
std :: normal_distribution
std :: cout urd (e4) "," nd (e4) std :: endl;
std :: cout std :: endl;
sistem ("pavza");
vrnitev 0;
} 




