Formalno je oblikovna datoteka dobila vsebino PHP je podobna datoteki, vendar pa prebere vsebino v niz, namesto v niz vrstic, in vam omogoča, da določite premik v datoteki, iz katere želite začeti branje.
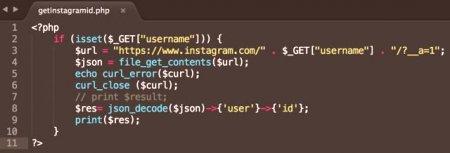
Sintaksa in primer uporabe

Običajno je preprostejša različica datoteke dobila vsebino PHP se uporablja:

. Naveden je določen URL. Pravzaprav je stran
predstavljena s PHP phpinfo () konstruktom, tj. Besedilo iz treh vrstic ni prebrano in rezultat te funkcije.
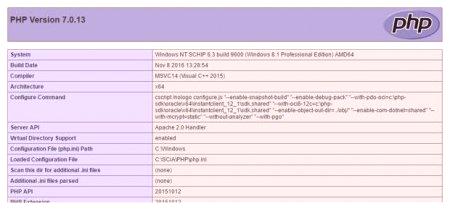 Kot je razvidno, je rezultat popolna stran, medtem ko PHP gradi vsebino datoteke na http (http) je prebral in posnel notranjo vsebino te strani v spremenljivki $ cLine.
Upoštevati je treba, da uporaba parametra $ context odpira velike priložnosti.
Kot je razvidno, je rezultat popolna stran, medtem ko PHP gradi vsebino datoteke na http (http) je prebral in posnel notranjo vsebino te strani v spremenljivki $ cLine.
Upoštevati je treba, da uporaba parametra $ context odpira velike priložnosti.
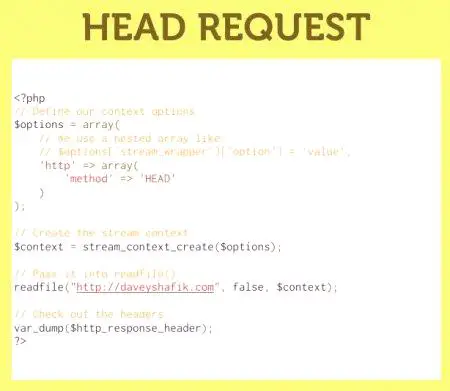 V običajni praksi uporaba vseh parametrov, razen $ filename, ni priljubljeno pravilo. Vendar pa je vrednost ustvarjenaStruktura stream_context_create (), ki se uporablja kot parameter $ context, omogoča pisanje precej zapletenih algoritmov za pridobivanje zahtevanih informacij. Različni datotečni sistemi, ovojnice zahtevajo različne nastavitve in možnosti za opis konteksta. Ustvari se lahko s konstrukti stream_context_create (stream_context_set_option, stream_context_set_params).
Namesto posebnega naslova URL lahko parameter $ filename predstavlja ime spremenljivke. To vam omogoča, da analizirate vsebino strani v samodejnem programabilnem načinu, poiščete imena strani, prepoznate povezave, dobite informacije, ki jih potrebujete.
V običajni praksi uporaba vseh parametrov, razen $ filename, ni priljubljeno pravilo. Vendar pa je vrednost ustvarjenaStruktura stream_context_create (), ki se uporablja kot parameter $ context, omogoča pisanje precej zapletenih algoritmov za pridobivanje zahtevanih informacij. Različni datotečni sistemi, ovojnice zahtevajo različne nastavitve in možnosti za opis konteksta. Ustvari se lahko s konstrukti stream_context_create (stream_context_set_option, stream_context_set_params).
Namesto posebnega naslova URL lahko parameter $ filename predstavlja ime spremenljivke. To vam omogoča, da analizirate vsebino strani v samodejnem programabilnem načinu, poiščete imena strani, prepoznate povezave, dobite informacije, ki jih potrebujete.
 Ustvarite lahko lasten razčlenjevalnik spletnega mesta, iskalnik in pišete porazdeljene programe za obdelavo informacij. Naloga je aktualna, zanimiva in praktična.
Ni problema, kaj natančno brati datoteko. V naslednjem kompleksnem načrtu je vsebina datoteke get php primer dejstva, da je datoteko "vordovsky" mogoče prebrati brez težav:
Ustvarite lahko lasten razčlenjevalnik spletnega mesta, iskalnik in pišete porazdeljene programe za obdelavo informacij. Naloga je aktualna, zanimiva in praktična.
Ni problema, kaj natančno brati datoteko. V naslednjem kompleksnem načrtu je vsebina datoteke get php primer dejstva, da je datoteko "vordovsky" mogoče prebrati brez težav:
 Tukaj je kompleksen dokument, ki se uporablja za testiranje knjižnice PHPOffice /PHPWord. Datoteka MS Word (* .docx) je znana kot arhiv zip, znotraj katere informacije temeljijo na standardu Open XML. Značilno je, da so datoteke z dokumenti dovolj velike in zapletene, vendar pa datoteka dobi strukturo vsebine, ki jo PHP lahko obravnava brez težav. Specifičnost tega primera je, da je obdelava dokumentov zgolj sredstvo knjižnice PHPOffice /PHPWord, ki vam ne omogoča pridobitve potrebnih zmogljivosti in preprosto ni mogoče zaporedno prebrati datoteke. VPodani dokument vse njegove elemente (besede, odstavke, formule, risbe, elemente črkovanja) so opisani z vrsto oznak, nekateri pa so lahko predstavljeni z zaporedjem ugnezdenih objektov.
Tukaj je kompleksen dokument, ki se uporablja za testiranje knjižnice PHPOffice /PHPWord. Datoteka MS Word (* .docx) je znana kot arhiv zip, znotraj katere informacije temeljijo na standardu Open XML. Značilno je, da so datoteke z dokumenti dovolj velike in zapletene, vendar pa datoteka dobi strukturo vsebine, ki jo PHP lahko obravnava brez težav. Specifičnost tega primera je, da je obdelava dokumentov zgolj sredstvo knjižnice PHPOffice /PHPWord, ki vam ne omogoča pridobitve potrebnih zmogljivosti in preprosto ni mogoče zaporedno prebrati datoteke. VPodani dokument vse njegove elemente (besede, odstavke, formule, risbe, elemente črkovanja) so opisani z vrsto oznak, nekateri pa so lahko predstavljeni z zaporedjem ugnezdenih objektov.
Če vzamete primer dokumenta (* .docx) s tabelami, se situacija sploh ne reši, če datoteko obdelate zaporedoma. Zahteva vsaj dve poti skozi telo dokumenta, če na primer ne greste, na primer, ko so tabele vgrajene druga v drugo.
Če branje kompleksnih datotek ne povzroča težav, je težava pri delu s preprostimi datotekami. Najprej morate vzeti aksiom: struktura datoteke dobi vsebino, ki jo PHP bere pravilno. Tudi če ne uporabljate teh ali drugih parametrov, bo najpreprostejša različica njene aplikacije vedno delovala, kot bi morala. Težave povzročajo kotne oklepaje in kodiranje datotek. Delo znotraj algoritma je treba razlikovati od prikaza rezultata v oknu brskalnika. Vrstica
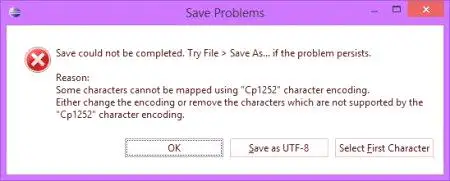 Naslednji trenutek: kodiranje datotek. Ni vedno preprosta besedilna datoteka ne povzroča težav. Če se bere besedilna informacija, lahko prisotnost n črk povzroči težave
Naslednji trenutek: kodiranje datotek. Ni vedno preprosta besedilna datoteka ne povzroča težav. Če se bere besedilna informacija, lahko prisotnost n črk povzroči težave
Možnosti in kontekstne nastavitve
Masovna obdelava strani
Branje besedilnih datotek
Če vzamete primer dokumenta (* .docx) s tabelami, se situacija sploh ne reši, če datoteko obdelate zaporedoma. Zahteva vsaj dve poti skozi telo dokumenta, če na primer ne greste, na primer, ko so tabele vgrajene druga v drugo.
Težave s kodiranjem in posebnimi znaki
- $ cLine = scChangeLTGT ($ cLine) - pokliče funkcijo pretvarjanja para vogalnih oklepajev v poseben znak na sliki s primerom oddelčne datoteke. Pisanje te funkcije ni nujno potrebno, vendar je pomembno, da upoštevate, da lahko informacije o branju vsebujejo oznake XML in HTML, kar zahteva posebno pozornost.
. $ cLine = iconv ('UTF-8', 'CP1251',$ cLine). V tem kontekstu uporaba funkcije iconv () s pravilno smerjo konverzije ni pomembna le za PHP "dobite vsebino datoteke http: //", da preberete stran mesta, ampak tudi, ko se prebere običajna lokalna datoteka. Če rezultat branja "ni viden", je prva stvar preverjanje kodiranja znakov.