Po podatkih Mednarodne telekomunikacijske zveze je v letu 2016 internet z določeno stopnjo pravilnosti uporabljalo tri in pol milijarde ljudi. Večina sploh ne misli, da so sporočila, ki jih pošiljajo prek osebnih računalnikov ali mobilnih pripomočkov, kot tudi besedila, prikazana na različnih monitorjih, dejansko kombinacije z 0 in 1. Takšna predstavitev informacij se imenuje kodiranje. Zagotavlja in močno olajšuje njegovo shranjevanje, obdelavo in prenos. Leta 1963 je bil razvit ameriški kodirni sistem ASCII, ki je tudi posvečen temu članku.
Predstavitev informacij v računalniku
Z vidika katerega koli računalnika je besedilo niz ločenih znakov. Vključujejo ne le črke, vključno z velikimi, temveč tudi ločila, številke. Poleg tega so posebni znaki "=", "& amp;", "(" in presledki). Niz znakov, iz katerih je sestavljeno besedilo, se imenuje abeceda, njihovo število pa je moč (označena kot N). = 2 ^ b, kjer je b število bitov ali informacijska teža določenega znaka. Dokazano je, da 256-znakovna abeceda omogoča predstavitev vseh potrebnih znakov. se imenuje 1 bajt, zato je običajno reči, da je binarna koda v besedilu, shranjenem vračunalnik, vzame en bajt pomnilnika.
Kako se izvaja kodiranje
Vsako besedilo se vnese v pomnilnik osebnega računalnika s pomočjo tipke na tipkovnici, ki vsebuje številke, črke, ločila in druge znake. V RAM-u se prenašajo v binarni kodi, kar pomeni, da je vsak znak osebi znana desetmestna koda od 0 do 255, ki ustreza binarni kodi od 00000000 do 11111111.
Kodiranje znakov odprtosti omogoča izvršitvenemu procesorju Obdelava besedila se nanaša na vsak znak posebej. Hkrati je dovolj 256 znakov, ki predstavljajo kakršnekoli simbolne informacije.
Kodiranje znakov ASCII
Ta kratica v angleščini se razlaga kot ameriška standardna koda za izmenjavo informacij. Tudi ob zori računalništva je postalo očitno, da lahko ustvarite različne načine za kodiranje informacij. Vendar je bilo za prenos informacij z enega računalnika na drugega potrebno razviti enoten standard. Leta 1963 se je v ZDA pojavila tabela ASCII kodiranja. V njej je vsak znak računalniške abecede umeščen v korespondenco z njegovo serijsko številko v binarni predstavitvi. Na začetku je bilo kodiranje ASCII uporabljeno samo v Združenih državah, nato pa je postalo mednarodni standard za osebne računalnike.
Kazalo vsebine
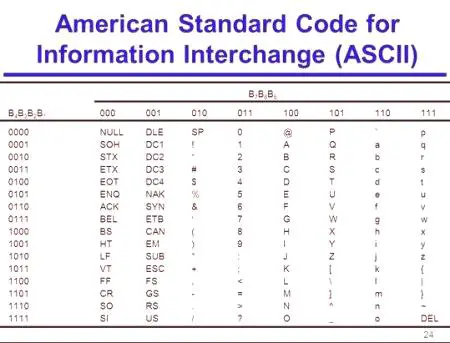
Kode ASCII so razdeljene v dva dela. Mednarodni standard velja samo za prvo polovico te tabele. Vsebuje znake z zaporednimi številkami od 0 (kodirani kot 00000000) do 127 (koda 01111111).
Zaporedna številka N
Kodiranje ASCII Besedilo
Simbol
0 - 31
00000000 - 00011111
37)
Simboli iz N od 0 do 31 se imenujejo kontrolorji. Njihova naloga je, da usmerjajo postopek izpisovanja besedila na monitor ali tiskalno napravo, zvočni signal itd.
32 - 127
00100000 - 01111111
Znaki od N od 32 do 127 (standardni del tabele) so zgornje in male črke latinske abecede, 10 števk, ločila in različni oklepaji, komercialni itd. znakov Simbol 32 je označen s presledkom.
128 - 255
10000000 - 11111111
Simboli od N od 128 do 255 nadomestni del tabele ali kodne strani) lahko imajo različne možnosti, od katerih ima vsaka svojo številko. Kodna stran se uporablja za označevanje nacionalnih abeced, ki se razlikujejo od latinščine. Še posebej uporablja kodiranje ASCII za ruske znake.
V tabeli za kodiranje sledijo črke velike in male črke, po abecednem vrstnem redu, številke pa z naraščanjem vrednosti. To načelo ostaja za rusko abecedo.
Kontrolni znaki
Tabela kodiranja ASCII je bila prvotno ustvarjena za sprejemanje in posredovanje informacij preko dolge neuporabljene naprave, kot je teletype. V tej povezavi so bili v nabor znakov vključeni neprevedeni, uporabljeni kot ukazi za nadzor te naprave. Podobne ekipe so bile uporabljene tudi pri računalniško podprtih metodah sporočanja, kot so Morseova koda itd.
Najpogostejši "teletype"simbol je NUL (00 "nič"). Še vedno se uporablja v večini programskih jezikov in označuje konec vrstice.
Kje uporabiti kodiranje ASCII
Ameriška standardna koda ni potrebna samo za vnos besedilnih podatkov s pomočjo tipkovnice. Uporablja se tudi v grafu. V programu ASCII Art Maker je slika različnih razširitev spekter kodiranja znakov ASCII. Podobni izdelki so lahko dveh vrst: opravljajo funkcijo grafičnih urejevalnikov s pretvorbo slike v besedilo in pretvorbo "risb" v ASCII graf. Na primer, dobro znani nasmeh je živ primer primera za kodiranje.
ASCII se lahko uporablja tudi pri ustvarjanju dokumenta HTML. V tem primeru lahko vnesete določen nabor znakov in ko pogledate stran, se prikaže simbol, ki ustreza tej kodi. ASCII je potreben tudi za ustvarjanje večjezičnih spletnih mest, saj se znaki, ki niso del posebne nacionalne tabele, nadomestijo z ASCII kodami.
Nekatere funkcije
Za kodiranje besedilnih informacij v kodiranju ASCII, je bilo prvotno uporabljenih 7 bitov (eden je ostal prazen), danes pa deluje kot 8-bitni. Črke, ki se nahajajo v stolpcih na vrhu in na dnu, se med seboj razlikujejo le en sam bit. To močno zmanjšuje kompleksnost testa.
Uporaba Microsoft Office ASCII
Če je potrebno, lahko tovrstno kodiranje besedilnih informacij uporabljajo Microsoftovi urejevalniki besedil, kot so beležnica in Office Word.Vendar pa pri vnašanju besedila v tem primeru ne bo mogoče uporabiti nekaterih možnosti. Na primer, ne boste mogli dodeliti v krepkem tisku, saj kodiranje ASCII ohranja samo vsebino informacij, ne upošteva pa celotnega videza in oblike.
Standardizacija
ISO je sprejel standarde ISO 8859. Ta skupina opredeljuje 8-kodno kodiranje za različne jezikovne skupine. ISO 8859-1 - Razširjeni ASCII je zlasti tabela za ZDA in zahodnoevropske države. ISO 8859-5 je tabela, ki se uporablja za cirilico, tudi za ruski jezik. Iz številnih zgodovinskih razlogov se je ISO 8859-5 uporabljal zelo kratek čas. Za ruski jezik se trenutno uporablja kodiranje:
CP866 (kodna stran 866) ali DOS, ki se pogosto imenuje alternativno GOST kodiranje. Aktivno se je uporabljala do sredine 90-ih let prejšnjega stoletja. Trenutno praktično ni uporabljen. KOI-8. Kodiranje je bilo razvito v sedemdesetih in osemdesetih letih prejšnjega stoletja, trenutno pa je standardni standard za poštna sporočila v RuNetu. Pogosto se uporablja v operacijskih sistemih Unix, vključno z Linuxom. "Ruska" različica KOI-8 se imenuje KOI-8R. Poleg tega obstajajo različice za druge jezike, npr. Ukrajinske. Koda Stran 1251 (CP 1251 Windows-1251). Zasnovan s strani Microsofta za podporo ruskega jezika v okolju Windows. Glavna prednost prvega standarda CP866 je bila ohranitev psevdografskih znakov na enakih položajih kot pri razširjenem ASCII. Dovoljeno je, da teče brez spremembv tujini, kot je znani poveljnik Norton. Trenutno se CP866 uporablja za programe, razvite v sistemu Windows, ki deluje v celozaslonskem besedilnem načinu ali v poljih z besedilom, vključno z FAR Managerjem. Računalniška besedila, napisana v šifriranju CP866, so se v zadnjem času redko srečevala, toda natanko to se uporablja za ruska imena datotek v Vindousu.Unicode
Trenutno je najpogosteje uporabljeno to kodiranje. Kode Unicode so razdeljene na območja. Prvi (od U + 0000 do U + 007F) vključuje znake ASCII s kodami. Potem so tu še območja znakov različnih narodnosti, pa tudi ločila in tehnični simboli. Poleg tega so nekatere kode Unicode rezervirane v primeru potrebe po vključitvi novih simbolov v prihodnosti. Zdaj veste, da je v ASCII kodiranju vsak znak predstavljen kot kombinacija 8 ničel in enot. Za nestrokovnjake se te informacije morda zdijo nepotrebne in nezanimive, vendar ne želite vedeti, kaj se dogaja "v možganih" vašega računalnika?!