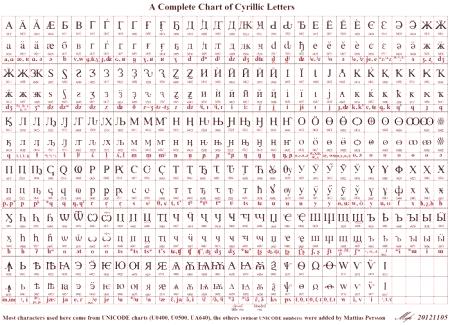
Unicode je mednarodni standard za kodiranje znakov, ki vam omogoča prikaz besedila na katerem koli računalniku na svetu na enak način, ne glede na jezik sistema, ki se uporablja na njem.
Osnove
Da bi razumeli, za kaj je potrebna tabela znakov Unicode, najprej razumemo mehanizem prikazovanja besedila na zaslonu monitorja. Računalnik, kot vemo, obdeluje vse informacije digitalno, vendar pa mora biti v grafiki prikazan za pravilno zaznavanje osebe. Da bi lahko prebrali to besedilo, moramo rešiti vsaj dve nalogi:
Kodirane natisnjene znake v digitalni obliki. Omogočiti operacijskemu sistemu, da primerja digitalno obliko z vektorskimi simboli, z drugimi besedami, da najde pravilne črke. Prvo kodiranje
Predhodnik vseh kodiranja je ameriški ASCII. Opisal je angleško abecedo z ločili in arabskimi številkami. Uporabljenih 128 znakov je postalo osnova za nadaljnji razvoj - uporabljena je tudi sodobna tabela znakov Unicode. Črke latinske abecede od takrat zavzamejo prve položaje v vsakem kodiranju.
Vsi ASCII-ji so omogočili shranjevanje 256 znakov, vendar je bilo prvih 128 v latinščini, preostalih 128 pa je bilo globalno uporabljenih za oblikovanje nacionalnih standardov. Na primer, v Rusiji, na njegovi podlagi so bili ustvarjeni CP866 in KOI8-R. Te spremembe so se imenovale razširitveRazličice ASCII.
Kodirane strani in Crazzybras
Nadaljnji tehnološki razvoj in pojav grafičnega vmesnika sta povzročila oblikovanje kodiranja ANSI s strani Ameriškega inštituta za standardizacijo. Za ruske uporabnike, zlasti z izkušnjami, je njegova različica znana kot Windows 1251. Najprej je predstavila koncept "kodne strani". S pomočjo kodnih strani, ki so vsebovale simbole nacionalnih abeced, razen latinščine, je obstajalo "medsebojno razumevanje" med računalniki, ki se uporabljajo v različnih državah.
Vendar pa je prisotnost velikega števila različnih kodiranja, ki se uporabljajo za isti jezik, začela povzročati težave. Bilo je tako imenovanih karkozybris. Nastale so zaradi neskladja med izvorno kodno stranjo, na kateri so bile določene informacije, in kodno stranjo, ki se privzeto uporablja na računalniku končnega uporabnika.
Kot primer se lahko navedejo zgoraj omenjeni kodirni koder CP866 in KOI8-R. Črke v njih so se razlikovale po kodnih položajih in načelih umestitve. V prvem so bili razvrščeni po abecednem vrstnem redu, v drugem pa na samovoljno. Lahko si predstavljate, kaj se je dogajalo pred očmi uporabnika, ki je poskušal odpreti takšno besedilo, ne da bi imel kodno stran, ki jo želite, ali pa jo je računalnik napačno interpretiral.
Ustvarjanje Unicode
Širjenje interneta in sorodnih tehnologij, kot je elektronska pošta, je privedlo do dejstva, da je besedilna sporočila na koncu prenehala ustrezati vsem. Vodilna podjetja na tem območjuIT je ustvaril konzorcij Unicode (konzorcij Unicode), ki ga je tabela simbolov uvedla leta 1991 pod imenom UTF-32.

Vendar pa prva univerzalna tabela znakovnih kod Unicode UTF-32 ni bila široko porazdeljena. Glavni razlog je bila redundanca shranjenih podatkov. Hitro je bilo izračunano, da bo besedilo v državah, ki uporabljajo latinsko abecedo, kodirano z novo univerzalno preglednico, štirikrat več prostora kot uporaba razširjene ASCII tabele.