Pridobivanje tečajev o SEO promociji, novinci se srečujejo z velikim številom razumljivih in ne pravočasnih. Vsega tega ni lahko razumeti, še posebej, če je bilo sprva slabo razloženo ali izgubljeno nekaj trenutkov. Upoštevajte vrednost v datoteki robots.txt Disallow, ki zahteva ta dokument, kako jo ustvariti in delati z njim.
S preprostimi besedami
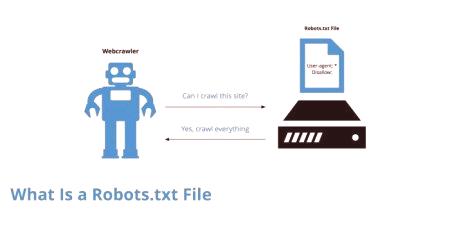
Da ne bi "hranili" bralca s kompleksnimi pojasnili, ki se običajno nahajajo na specializiranih straneh, je bolje, da vse razložite "na prste". Iskalnik prispe na vaše spletno mesto in indeksira strani. Ko vidite poročila, ki kažejo na težave, napake itd.
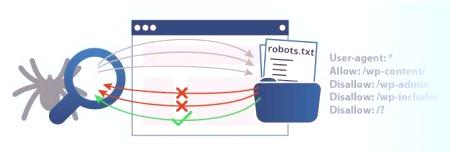
Vendar imajo mesta tudi takšne informacije, ki niso potrebne za statistiko. Na primer, stran »Podjetje« ali »Stiki«. Vse to je neobvezno za indeksiranje, v nekaterih primerih pa je nezaželeno, ker lahko izkrivlja statistiko. Da bi se temu izognili, je najbolje, da te strani zaprete od robota. Prav to zahteva ukaz v datoteki robots.txt Disallow.
Standard
Ta dokument je vedno na voljo na straneh. Njegovo ustvarjanje obravnavajo razvijalci in programerji. Včasih lahko to storijo tudi lastniki vira, zlasti če je majhen. V tem primeru delo z njim ne traja veliko časa. Robots.txt se imenuje standard za izključitev iskalnika. Predstavljen je z dokumentom, v katerem so predpisane glavne omejitve. Dokument je postavljen v korenino vira. V tem primeru, tako da ga lahko najdete ob poti "/robots.txt". Čevir ima več poddomen, potem je ta datoteka postavljena na koren vsakega od njih. Standard je nenehno povezan z drugim - zemljevidi spletnih mest.
Zemljevid strani
Da bi razumeli celotno sliko o tem, o čemer razpravljamo, nekaj besed o zemljevidih spletnega mesta. To je datoteka, napisana v XML. Vsebuje vse podatke o viru za PS. Po dokumentu lahko spoznate spletne strani, ki jih dela indeksirajo.
Datoteka omogoča hiter dostop do PS na kateri koli strani, prikazuje najnovejše spremembe, pogostost in pomembnost PS. V skladu s temi merili robot najbolj pravilno pregleda mesto. Vendar je pomembno razumeti, da prisotnost takšne datoteke ne zagotavlja, da so vse strani indeksirane. To je bolj namig na poti k temu procesu.
Uporaba
Pravilna datoteka robots.txt se uporablja prostovoljno. Standard se je pojavil leta 1994. Konzorcij W3C ga je sprejel. Od tega trenutka se je začel uporabljati na skoraj vseh iskalnikih. To je potrebno za "dozirano" prilagajanje pregledovanja virov s strani iskalnega robota. Datoteka vsebuje nabor navodil, ki uporabljajo FP. Zahvaljujoč kompletu orodij je enostavno namestiti datoteke, strani, imenike, ki jih ni mogoče indeksirati. Robots.txt kaže tudi na datoteke, ki jih je treba takoj preveriti.
Zakaj?
Kljub dejstvu, da se datoteka dejansko lahko uporablja prostovoljno, jo ustvarijo praktično vsa mesta. To je potrebno za racionalizacijo dela robota. V nasprotnem primeru bo preveril vse strani v naključnem vrstnem redu in poleg tega, da lahko preskoči nekatere strani, ustvari veliko obremenitevvir Datoteka se uporablja tudi za skrivanje pred očmi iskalnika:
Strani z osebnimi podatki obiskovalcev.
Strani, ki vsebujejo obrazce za pošiljanje podatkov itd.
Ogledala.
Strani z rezultati iskanja.
Če ste za določeno stran določili datoteko robots.txt Disallow, obstaja možnost, da bo še vedno prikazana v iskalniku. Ta možnost se lahko pojavi, če je povezava na stran nameščena na enem od zunanjih virov ali znotraj vašega spletnega mesta.
Direktive
Ko govorimo o prepovedi iskalnika, se pogosto uporablja izraz "direktive". Ta izraz je znan vsem programerjem. Pogosto se nadomesti s sinonimom "navodil" in se uporablja v povezavi z "ukazi". Včasih je lahko predstavljen z nizom konstrukcij programskih jezikov. Direktiva Disallow v datoteki robots.txt je ena najpogostejših, vendar ne edina. Poleg tega obstaja še nekaj drugih, ki so odgovorni za določena navodila. Na primer, obstaja uporabniški agent, ki prikazuje robote iskalnikov. Dovolite, da je nasprotni ukaz prepovedan. Označuje dovoljenje za pajkanje nekaterih strani. Nato si poglejmo osnovne ukaze.
Vizitka
Seveda v datoteki robots.txt, User Agent Disallow ni edina direktiva, ampak ena izmed najpogostejših. Sestavljen je iz večine datotek za majhne vire. Vizitka za kateri koli sistem je še vedno ukaz za agenta uporabnika. To pravilo je zasnovano tako, da kaže na robote, ki gledajo na navodila, ki bodo zapisana v dokumentu. Trenutno je na voljo 300 iskalnikov. Če želite, da vsak slediPo nekaterih navedbah ne bi smeli vse pisati. Dovolj je, da podate "Uporabniški agent: *". "Asterisk" v tem primeru prikaže sisteme, da so takšna pravila namenjena vsem iskalnikom. Če ustvarjate navodila za Google, morate določiti ime robota. V tem primeru uporabite Googlebot. Če je v dokumentu podano samo ime, drugi iskalniki ne bodo sprejeli ukaza datoteke robots.txt: Disallow, Allow, itd. Predvidevajo, da je dokument prazen in da zanje ni navodil.
Celoten seznam botnamov najdete na internetu. To je zelo dolgo, zato, če potrebujete navodila za določene Googlove storitve ali Yandex, boste morali določiti določena imena.
Prepoved
O naslednji skupini smo že večkrat govorili. Disallow določa samo, katere informacije robot ne sme prebrati. Če želite iskalnikom prikazati vso vsebino, napišite »Disallow:«. Tako bo delo pregledalo vse strani vašega vira. Popolna prepoved indeksiranja datoteke robots.txt "Disallow: /". Če pišete na ta način, potem delo sploh ne bo skeniralo vira. To se ponavadi opravi v začetnih fazah, pri pripravi na začetek projekta, v poskusih itd. Če je spletno mesto pripravljeno, da se prikaže, potem spremenite to vrednost, da se bodo uporabniki z njo lahko seznanili. Na splošno je ekipa univerzalna. Lahko blokira nekatere elemente. Na primer, mapa z ukazom Disallow: /papka /lahko prepoveduje pajkanje povezave do datoteke ali dokumentov določenega dovoljenja.
Dovoljenje
Dovoliti delopogledate določene strani, datoteke ali imenike z uporabo direktive Dovoli. Včasih je potreben ukaz, da lahko robot obišče datoteke iz določenega odseka. Na primer, če je to spletna trgovina, lahko določite imenik. Druge strani bodo skenirane. Vendar ne pozabite, da morate najprej zaustaviti pregledovanje celotne vsebine spletnega mesta, nato pa z odprtimi stranmi določite ukaz Dovoli.
Ogledala
Druga direktiva o gostiteljih. Ne uporabljajo ga vsi spletni skrbniki. Potrebno je, če ima vaš vir ogledala. Potem je to pravilo potrebno, saj označuje delo "Yandexa", na katerem je glavno ogledalo in ki ga je treba skenirati. Sistem se ne odbija in zlahka najde zahtevani vir v skladu z navodili, opisanimi v datoteki robots.txt. V datoteki je mesto zapisano brez navedbe "http: //", vendar le, če deluje na HTTP. Če uporablja protokol HTTPS, potem navede to predpono. Na primer, »Host: site.com«, če je HTTP ali »Host: https://site.com« v primeru HTTPS.
Navigator
O Sitemapih smo že govorili, ampak kot ločeno datoteko. Če pogledamo pravila za pisanje datoteke robots.txt s primeri, vidimo uporabo podobnega ukaza. Datoteka se nanaša na »Sitemap: http://site.com/sitemap.xml«. To storite tako, da robot preveri vse strani, ki so navedene na zemljevidu mesta na naslovu. Vsakič, ko se vrnete, bo robot videl nove posodobitve, spremembe in hitrejše pošiljanje podatkov iskalniku.
Dodatni ukazi
To so bile osnovne smernice, ki kažejo na pomembne in potrebne ukaze. Obstaja manj uporabnih, innavodila se ne uporabljajo vedno. Crawl-delay na primer določa obdobje, ki se uporablja med obremenitvami strani. To je potrebno za šibke strežnike, da jih ne bi "spravili" v robote robotov. Za določitev parametra se uporabljajo sekunde. Clean-param pomaga preprečevati podvajanje vsebine, ki se nahaja na različnih dinamičnih naslovih. Pojavijo se, če obstaja funkcija razvrščanja. To bo izgledalo takole: "Clean-param: ref /catalog/get_product.com".
Universal
Če ne veste, kako ustvariti pravi robots.txt - ni strašno. Poleg navodil obstajajo tudi univerzalne različice te datoteke. Lahko jih postavite na skoraj katero koli spletno stran. Izjema je lahko le velik vir. Toda v tem primeru morajo biti dokumenti znani strokovnjakom in jih vključiti v posebne ljudi.
Univerzalni niz direktiv vam omogoča, da odprete vsebino mesta za indeksiranje. Tu je ime gostitelja in prikazan je zemljevid mesta. Robotom omogoča, da vedno dostopajo do strani, ki jih je treba optično prebrati. Predpostavka je, da se podatki lahko razlikujejo glede na sistem, ki ga ima vaš vir. Zato je treba izbrati pravila, pri čemer je treba upoštevati vrsto spletnega mesta in CMS. Če niste prepričani, da je datoteka, ki ste jo ustvarili, pravilna, jo lahko preverite v orodjih Google Webmaster Tools in Yandex.
Napake
Če razumete, kaj pomeni Disallow v datoteki robots.txt, to ne zagotavlja, da ne boste naredili napak pri izdelavi dokumenta. Obstajajo številne tipične težave, s katerimi se srečujejo neizkušeni uporabniki. Pogosto zamenjujejo vrednost direktive. Morda jepovezan z nerazumevanjem in nevednostjo navodil. Morda ste ga zgolj prezrli in prekinili brezbrižnost. Na primer, lahko uporabijo "/" za User-agent in za Disallow ime je robot. Prenos je še ena pogosta napaka. Nekateri uporabniki verjamejo, da je treba seznam prepovedanih strani, datotek ali map našteti enega za drugim. Pravzaprav morate za vsako prepovedano ali dovoljeno povezavo, datoteko in mapo znova zapisati ukaz in iz nove vrstice. Napake lahko povzroči napačno ime same datoteke. Ne pozabite, da se imenuje "robots.txt". Uporabite male črke za ime, brez sprememb, kot so "Robots.txt" ali "ROBOTS.txt".
Polje uporabniškega agenta mora biti vedno izpolnjeno. Ne puščajte te direktive brez ukaza. Ko se znova vrnete na gostitelja, ne pozabite, da če spletno mesto uporablja HTTP, ga ni treba podati v ukazu. Samo če je to napredna različica HTTPS. Direktive Disallow ne morete pustiti nesmiselne. Če je ne potrebujete, preprosto ne usmerjajte.
Sklepi
Če povzamemo, je vredno reči, da je robots.txt standard, ki zahteva natančnost. Če tega še niste doživeli, boste v zgodnjih fazah ustvarjanja imeli veliko vprašanj. Najbolje je, da to delo posredujete spletnim skrbnikom, ker ves čas delajo z dokumentom. Poleg tega lahko pride do nekaterih sprememb v dojemanju direktiv s strani iskalnikov. Če imate majhno spletno stran - majhno spletno trgovino ali blog - potem bo dovolj, da preučite to vprašanje in vzamete enega od univerzalnih primerov.