Tehnologijo OCR (Optical Character Recognition) lahko uporabite za pretvorbo tiskanega dokumenta v elektronsko različico. Na primer, če se multipagentni primer pregleda v datoteko TIFF, se naloži v program OCR, ki prepozna besedilo in ga nato pretvori v datoteko, ki jo je mogoče urediti. Nekateri programi omogočajo pregledovanje strani in pretvorbo vsebine v dokument v enem koraku. Čeprav je bila tehnologija prvotno razvita za optično prepoznavanje znakov, se lahko uporablja tudi za ročno napisane znake. Na primer, poštne storitve, kot je USPS, uporabljajo programsko opremo OCR za samodejno obdelavo pisem in paketov z branjem naslova.
Področja uporabe OCR
OCR se dekodira kot optično prepoznavanje znakov. To je razširjena tehnologija za prepoznavanje besedila znotraj slik kot skeniranih dokumentov in fotografij. Tehnologija se uporablja za pretvorbo skoraj vseh vrst slik, ki vsebujejo pisno, ročno napisano ali natisnjeno besedilo, v strojno berljive besedilne podatke.
OCR je postal priljubljen v zgodnjih devetdesetih letih, ko je poskušal digitalizirati zgodovinski material. Od takrat je metoda doživela pomembne izboljšave in trenutno zagotavlja skoraj popolno natančnost optičnega prepoznavanja znakov. Napredne tehnike, kot je Zonal OCR, se uporabljajo za avtomatizacijo kompleksnih delovnih procesov, ki temeljijo napretvorbo tipiziranih besedil v digitalne dokumente. Po obdelavi skeniranega gradiva lahko besedilo urejate s programi, kot sta Microsoft Word ali Google Dokumenti, ki so urejevalniki besedila. Preden se je pojavila ta tehnologija, je bil edini način za digitalizacijo tiskanih dokumentov ročno vnašanje besedila. Ne samo, da je potreboval veliko časa, temveč je povzročil tudi netočnosti in napake pri reprodukciji kopije. OCR se pogosto uporablja kot "skrita" tehnologija v mnogih znanih sistemih in storitvah, ki vključujejo avtomatizacijo vnosa podatkov in indeksiranje za iskalnike, avtomatsko optično prepoznavanje znakov registrskih tablic, kot tudi pomoč slepim in slabovidnim osebam.
Postopek določanja točnosti besedila
Vsak korak postopka OCR je pomemben za določanje točnosti končnega besedila. Začne se s pretvorbo tiskanega dokumenta. Če ima sledove, lise in slab kontrast, bo programska oprema naredila napake pri prepoznavanju in rezultat se bo izkazal za napačnega. Da bi se izognili tem težavam, lahko naredite izboljšano fotokopijo tiskanja. Prva faza dela je skeniranje natisnjenega besedila. Programska oprema OCR deluje s slikovnimi datotekami. Skener ali dober digitalni fotoaparat ustvarja jasne fotokopije dokumentov. Boljše je, da pretvorite skenirane datoteke v črno-belo. Proces je binaren. Če je na sliki črna barva, se prepozna prepoznavanje besedila OCR, bela pa deluje kot ozadje. Druga faza jeopredelitev znakov Hitrost tega postopka je odvisna od programa OCR, ki ga uporabljate. Večina jih analizira posamezne elemente. Namen programa je prepoznati znake, vendar pa dobri programi ne prepoznajo samo besedila, temveč tudi tabele in druge elemente postavitve. Postopek ni popoln, saj na točnost vpliva veliko dejavnikov. Kateri programi so namenjeni optičnemu prepoznavanju znakov, bomo obravnavali spodaj. Uporabnik pa lahko prosto izbere tisto, kar je najbolje. OCR-ji imajo vgrajene funkcije za preverjanje črkovanja in označujejo zavajajoče besede. Nekateri so tako zapleteni, da označujejo neusklajenost besed in slovničnih napak, uporabnik pa mora narediti le potrebno prilagoditev. Zadnji korak je shranjevanje dokončanega dokumenta v pravem formatu. Če aplikacija ne zahteva, lahko izkoristite številne brezplačne spletne konvektorje.
Optična tehnologija za Brailovo pisavo
\ t
Tehnologija optičnega prepoznavanja znakov (OCR) omogoča slepim in slabovidnim osebam, da določijo besedilo in ga izgovarjajo na glas. Ta uporablja jezikovni izpis in prikaže informacije na Braillovem zaslonu. Obstajajo trije glavni elementi sistema za optično prepoznavanje znakov: pridobivanje slik, prepoznavanje in branje besedila. Najprej se natisne dokument, ki ga zajame kamera, nato pa ga programska oprema OCR pretvori v prepoznavne znake in besede, nato pa sintetizator v sistemu izgovori določen material na glas ali prikaže na Braillovem zaslonu. Informacije lahkoelektronsko shranjena v napravi s programsko opremo OCR ali v pomnilniku samostojne naprave. Proces upošteva logično strukturo jezika. Sistem bo sklenil, da je na primer sindikat "to" na začetku predloga napaka in ga je treba brati kot "to". Uporablja besedišče in uporablja metode preverjanja, podobne tistim, ki se uporabljajo v številnih urejevalnikih besedil. Vsi sistemi OCR ustvarjajo začasne datoteke, ki vsebujejo znake in postavitve strani. V nekaterih sistemih jih je mogoče pretvoriti v oblike, ki jih je mogoče najti z običajnimi računalniškimi aplikacijami, kot so urejevalnik besedila, preglednice in baze podatkov.
Izbira programov za prepoznavanje besedila
\ t
Priporočljivo je, da namerno pristopite k izbiri programske opreme za prepoznavanje besedila. Najbolje je, da se preizkusite ali upoštevate mnenje naprednih uporabnikov. Testiranje se izvaja ob upoštevanju naslednjih dejavnikov:
Natančnost je tisto, kar loči dober OCR od slabega. Vendar pa je nerealno pričakovati 100% natančnost programa za prepoznavanje rokopisa. Dejavniki, kot so kakovost izvirnih dokumentov in ločljivost slike, pomembno vplivajo na končni rezultat. Dobri OCR-ji dosegajo 98%, če uporabljamo sodoben skener in izvorno kodo v zadovoljivem stanju.
Večjezičnost - Danes ima ta lastnost večina programov. OCR pregleda ločen znak, da ga prepozna. Če je zasnovan tako, da prepozna samo angleške črke, potem ne bo mogelnatančno interpretirati posebne znake, na primer črke, kot so črke, ki poudarjajo "e". Ti znaki bodo predstavljeni z najbližjim ekvivalentom v angleščini. Pri uporabi aplikacije, ki podpira večjezičnost, je določen jezik dokumenta, da se zagotovi natančnost priznavanja.
Podpora za rokopis. Besedilo, ustvarjeno s tipkovnico, je zlahka prepoznano s katerim koli programom. Vendar pa je rokopis popolnoma drugačen način skeniranja. Ljudje imajo zelo različne rokopise. Nekateri pišejo lepo, medtem ko večina rokopisa ni dovolj čitljiva. Kvalitativni OCR-ji lahko prepoznajo vsak rokopis. Za arhiviranje rokopisnega gradiva potrebujete programe za rokopis.
Stopnja avtomatizacije. OCR se lahko zažene samodejno ali interaktivno. Če morate pregledati več strani hkrati, je najbolje, da razmislite o samodejnih programih. S to funkcijo lahko dokumente skenirate v več klikih med opravljanjem drugih opravil, tako da je enostavno najti nastalo datoteko PDF, txt ali doc. Večina programov za prosto prepoznavanje besedila ima omejeno avtomatizacijo.
Ohranjanje postavitve. Glavni namen teh programov je prevajanje besedila v elektronsko obliko. Nekateri ne ohranijo postavitve izvirnega dokumenta. Zato je potrebno dolgo časa urediti končno različico. Dober program mora shraniti prvotno postavitev, nato pa je v končni kopiji potrebna manjša kopija. Takšni programi shranjujejo stolpce tabel in grafične slike, kot v izvirni različici.
Popular Mobile Software
OCR je odličen za prenos besedila iz fizičnih virov neposredno v digitalni dokument. Obstajajo različne vrste aplikacij in aplikacij za namizne in mobilne naprave. So drugačne v ceni in imajo svoje ključne značilnosti.
Najbolj priljubljeni skenerji za Android:
Office Lens - omogoča brezplačno skeniranje strani in OCR za uporabnike Androidov. Za pretvorbo morate vzpostaviti povezavo z internetom.
PDF skenerji (na primer, ABBYY TextGrabber, CamScanner, MDScan, OCR v trenutku) - opravijo skeniranje z naslednjim OCR. Na številu skeniranih strani in vodnih žigov ni omejitev.
Spletni OCR. Najdete ga na internetu, storitev je zelo preprosta in enostavna za uporabo. Posebnost je, da podpira 46 jezikov, izhodni dokument tehta več kot 5 MB, preprosto pa je pretvoriti v Microsoft Word, Excel ali obliko navadnega besedila. Po registraciji lahko pretvorite več strani PDF, RTF, Excel in datoteke do 100 MB. Za velike količine priznanja obstaja plačana različica.
Google Dokumenti
Za tiste, ki že poznajo Googlove dokumente, lahko uporabite OCR, vgrajen v Google Drive. Da bi dosegli najboljše rezultate, mora biti pisava nastavljena na Arial ali Times New Roman. Rezultat lahko izboljšate tako, da poskrbite, da ima optično prebrana slika enakomeren in jasen kontrast. Fotografski materiali se lahko obdelujejo posamezno v JPG, PNG, GIF ali v večstranskih dokumentih PDF. Razširitev podpira večino jezikov. Google ima veliko programov usposabljanja in zmogljivosti za obdelavo v oblaku. Mnogi uporabniki menijo, da storitev nima naprednih funkcij in možnosti. Če uporabljate aplikacijo Google Drive za Android, lahko strani optično preberete neposredno iz aplikacije s fotoaparatom v pametnem telefonu. V nasprotnem primeru prenesite dokumente z uporabo optičnega bralnika, ki je povezan z računalnikom, ali na drug način, da začnete obdelovati prepoznavanje v storitvi Google Drive. Za posameznike Google Drive ponuja brezplačno raven shranjevanja okrog 19 GB, ki omogoča razširitev do 100 GB prek storitve Google One za 199 evrov. ZDA
Optično priznavanje s strani Abbyy
Abbyy FineReader že dolgo dela z dokumenti. Je celovita rešitev za poslovne in navadne uporabnike. Omogoča vam, da dobite vse potrebne funkcije za pridobivanje vsebine besedil iz celovitega bralca, urejeno digitalizirano gradivo. Poleg prepoznavanja besedila in pretvorbe v dokumente PDF, Microsoft Office ali druge oblike jih lahko program primerja, doda opombe in komentarje. Abbyy FineReader lahko pretvori material v paketnem načinu in rokuje z mnogimi izhodnimi formati v 192 različnih jezikih. Obstajajo spremljajoče aplikacije za mobilne naprave, ko morate iz telefona hitro opraviti pregled. Programska oprema ni posodobljena, vendar je preprosta, funkcionalna in dobro deluje pri svojem delu. Pripomoček ima dober ugled kot ena najboljših možnosti na področju optičnega prepoznavanja znakov. Uporabite lahko brezplačno preizkusno različico. ZA19999 dolarjev ZDA na standardno enkratno trajno licenco. Če se zdi, da je nekdo draga možnost, lahko dober nadomestek za ABBYY FineReader - spletno različico. Omejen je na skeniranje samo 10 strani na mesec. Ampak prihaja z vsemi drugimi premium funkcijami. Za dostop boste morali registrirati. Podpira veliko formatov vhodnih datotek in lahko izberete izhodne datoteke, kot so PDF, Word, Excel, PowerPoint in e-Pub.
Storitev Cloud Acrobat
Adobe Acrobat izpolnjuje vse zahteve in ponuja impresiven seznam funkcij in možnosti, čeprav je cena nekoliko bolj strma kot konkurenca. Za vse funkcije optičnega prepoznavanja besedila izberite različico Pro Adobe Acrobat. DC je kratica za "Document Cloud" in se povsem jasno povezuje z rešitvijo Adobe cloud, če želite dostopati do datotek z vseh računalnikov. Obstaja tudi preprosta in brezhibna integracija z vsemi drugimi storitvami Adobe, kot je Photoshop. Če se uporabnik odloči plačati za različico Pro Adobe Acrobat DC, bo prejel vsa orodja za prepoznavanje besedila, sposobnost dodajanja komentarjev in povratnih informacij vsebini, specializirano storitev za pregledovanje tabel, sposobnost hitrega primerjanja dveh dokumentov skupaj. Materiale lahko urejate neposredno na zaslonu nekaj sekund po skeniranju. Adobeov logotip zagotavlja določeno raven kakovosti, uporabniki pa so navdušeni nad intuicijo in zmožnostmi programa Adobe Acrobat DC. Naročnina na storitev se začne pri $ 1.299. ZDA
Najboljša brezplačna programska oprema
Prosti OCR za Word je najboljša brezplačna programska opremaProgramska oprema za optično prepoznavanje znakov z uporabo najnovejših mehanizmov. Tesseract je najmočnejše orodje za to vrsto in velja za eno najbolj natančnih metod. Program podpira več formatov slik in TIFF na več straneh. Ta storitev je lahko popolnoma brezplačna za pridobivanje besedila iz priloženega foto materiala. Motor Tesseract je prvotno razvil Hewlett Packard Labs v letih 1985-1994. V letu 1996 so bile narejene nekatere spremembe. Leta 1995 je bil vključen v prve tri mehanizme priznavanja. Deluje z operacijskim sistemom Windows, Linux in Mac OS X. FreeOCR lahko obdeluje slike, ki imajo večjezično in večjezično besedilo. Obdeluje formate PDF in podpira naprave TWAIN, kot so skenerji, ima razširjen vmesnik z dvojnim oknom, ki ga je enostavno razumeti.
Prosti OCR za Word lahko prihrani veliko časa, ne da bi bilo treba znova vnesti že napisano delo. Program vzame dokument, skenirani predmet ali sliko in ga pretvori v berljiv, urejljiv in natančen material. Lahko ga prenesete brezplačno v Wordu. OCR v Word je optimiziran za delo z vsemi vrstami optičnih bralnikov in ima natančnost 98%, sodoben vmesnik, ki omogoča enostaven dostop do vseh opravil, obstajajo rotacijske funkcije, če fotografija ne ustreza pravilno na zaslonu. FOR izvleče besedilo iz posnetih slik s pomočjo pametnih telefonov ali digitalnih fotoaparatov z visoko natančnostjo in kakovostjo.
Prepoznavanje znakov v Linuxu
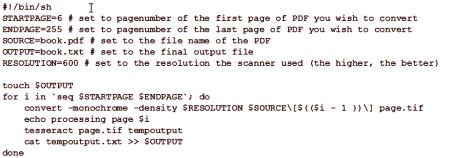
OCRFeeder suite nudi priročen grafični uporabniški vmesnik za Linux.ki je v bistvu zunanji vmesnik za nekatere slike, OCR in besedilna orodja, kot je tiskanje ali preverjanje črkovanja. Samih znakov ne bere, temveč uporablja druge OCR programe s tako imenovanimi nastavitvami "mehanizmov za prepoznavanje". Ima določene parametre za Tesseract, CuneiForm, GOCR in Ocrad. Uporabnik mora v Ubuntu namestiti samo motorje, ki jih izbere - enega ali več, nato pa jih zazna v nastavitvah podajalnika. Dodate lahko druge motorje in ročno spremenite te nastavitve. V eni aplikaciji je lahko več različnih motorjev. Glavno okno podajalnika vam omogoča, da izberete tisto, kar želite uporabiti za določeno industrijo, prav tako pa je nastavitev, ki jo izberete privzeto. Če želite izbrati jezik prebranega besedila, morate v primeru Tesseracta in CuneiForma v nastavitve tega motorja dodati stikalo -l na ustrezno kodo jezika /skripta, na primer "-l pol" za lak ali "-l dan-frak" za danščino. Tehnologija optičnega prepoznavanja natisnjenih znakov "Tesseract" v začetku je lahko prepoznala besedilo v angleščini, različica 2.x pa je bila večjezična. Če je potrebno, lahko namestite več kot en slovar. Nove različice digitalizirajo besedilo na podlagi ISO 963-2. Po uspešni namestitvi uporabite ukaz "tesseract & gt; image path & gt; osnovno ime izhodne datoteke". Tesseract samodejno doda izvorno datoteko .txt, določite možnost -l, ki ji sledi jezikovna koda. Za različice Tesseracta prej kot v tretjem, je zelo pomembno, da je bila slika malo v formatu datoteke z oznakamirazširitev ".tif", ne ".tiff". Ukazna vrstica mora izgledati takole: "$ tesseract ~ /input.tif output". Kjer je "input.tif" dokument preoblikovanja, ki se nahaja v domači mapi, in "output" je gradivo, ki ga bo Tesseract ustvaril kot "output.txt". Pogosto skenirana besedila se shranijo kot rastrska slika v velik dokument PDF. Z uporabo ImageMagicka lahko posamezne strani izvlečete kot TIFF datoteke za obdelavo iz Tesseracta. Naslednji skript lahko pomaga pri avtomatizaciji tega procesa.
Program CuneiForm je še en optični sistem za prepoznavanje besedila, ki je bil prvotno razvit in temelji na odprti kodni tehnologiji Cognitive. Različico operacijskega sistema Windows, ki ima svoj grafični vmesnik, lahko zaženete z nekaterimi rezultati v vinu. Njegova Linux vrata se razvijajo na Launchpadu in čeprav trenutno nima lastnega grafičnega vmesnika, se lahko CuneiForm uspešno zažene z grafičnim vmesnikom OCRFeeder. Spodaj je primer, kako uspešno pretvoriti nekaj posnetkov zaslonskih oglasnih desk .jpeg v uporabne besedilne datoteke na spletu.
Pdfocr je skript, ki izvaja OCR za večstranske datoteke PDF in ga izvaja kot plast besedila, ki ga je mogoče iskati. Tesseract ali klinasto obliko lahko uporabi kot mehanizem za prepoznavanje. Sam scenarij lahko dobite pri Githubu ali PPA. Če želite zagnati ukaz, zapišite v terminal: "pdfocr -i input.pdf -o output.pdf". Tehnologija OCR ne stoji več, dolgoročno priznava intelektualni sistem optičnega prepoznavanja znakov - ICR. Ta standard je napredoval. Odličnodel ICR ima sistem za samoučenje, imenovan nevronska mreža, ki samodejno posodablja bazo podatkov za nove vzorce rokopisa. Razširja uporabnost naprav za skeniranje za namene obdelave dokumentov od prepoznavanja natisnjenega besedila (funkcija OCR) do ročno napisanih materialov in lahko doseže več kot 97% natančnost pri branju pisanega gradiva v strukturiranih oblikah.