Stiskanje je zasebni primer kodiranja, katerega glavna značilnost je, da je dobljena koda manjša od izvirne. Proces temelji na iskanju ponovitev v nizu informacij in ohranjanju le enega skupaj s številom ponovitev. Tako se na primer, če se zaporedje pojavi v datoteki, kot je "AAAAAA", ki zavzema 6 bajtov, shrani kot "6A", ki zasede 2 bajta v algoritmu stiskanja RLE.
Zgodovina procesa
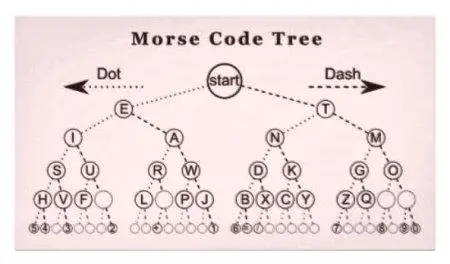
Morsejeva koda, izumljena leta 1838, je prvi znani primer stiskanja podatkov. Kasneje, ko so leta 1949 začeli pridobivati popularnost mainframe računalniki, so Claude Shannon in Robert Fano izumili kodiranje, poimenovano po avtorjih - Shannon-Fano. To šifriranje dodeljuje kode znakov nizu podatkov o teoriji verjetnosti.
Šele v sedemdesetih letih so bili s prihodom interneta in spletnega shranjevanja izvedeni popolni algoritmi stiskanja. Huffmanove kode se dinamično generirajo na podlagi vhodnih informacij. Ključna razlika med Shannon-Fano kodiranjem in Huffmanovim kodiranjem je, da je bila v prvem verjetnostnem drevesu zgrajena od spodaj navzgor, ustvarila je podoptimalen rezultat, v drugem pa od zgoraj navzdol. Leta 1977 sta Abraham Lempel in Jacob Zev izdala svojo inovativno metodo LZ77 z bolj posodobljenim besediščem. Leta 1978 je ista skupina avtorjev izdala izboljšan algoritem stiskanja LZ78. Kdo uporablja nov slovar, analizira vhodne podatke in generira statični slovar, namesto dinamičnega, kot v 77različica
Oblike izvajanja stiskanja
Stiskanje se izvaja s programom, ki uporablja formulo ali algoritem, ki določa, kako zmanjšati velikost podatkov. Predstavljajte si na primer niz bitov z manjšim nizom 0 in 1 z uporabo slovarja za pretvorbe ali formule. Stiskanje je lahko preprosto. Na primer, pri brisanju vseh nepotrebnih znakov vstavite podvojeno kodo, da označite niz ponovitev in zamenjate manjšo bitno sliko. Algoritem stiskanja datotek lahko zmanjša besedilno datoteko do 50% ali več. Za prenos se postopek izvaja v bloku prenosa, vključno s podatki o glavi. Kadar se informacije pošiljajo ali sprejemajo preko interneta, se lahko arhivske datoteke, same ali v kombinaciji z drugimi velikimi datotekami, prenašajo v ZIP, GZIP ali drugem "zmanjšanem formatu." Datoteka z velikostjo 20 megabajtov (MB) bo trajala 10 MB prostora, zaradi česar bodo skrbniki omrežja manj časa za shranjevanje podatkovnih zbirk
Optimizira varnostno kopiranje
Pomembna metoda za zmanjšanje podatkov. ]
Skoraj vsaka datoteka se lahko vnese vendar je pomembno, da izberete tehnologijo, ki jo želite za določeno vrsto datoteke, sicer lahko datoteke zmanjšate, vendar se splošna velikost ne spremeni.
Uporabljeni sta dve vrsti metod - algoritmi stiskanja brez izgube in brez izgube. Prvi vam omogoča, da datoteke obnovite v izvirno stanje, ne da bi izgubili en bit podatkov v stisnjeni datoteki. Drugi je tipičen pristopizvršljive datoteke, besedila in preglednice, kjer bodo izgubljene besede ali številke spremenile informacije. Kompresija izgube trajno odstrani bitove podatkov, ki so odvečni, nepomembni ali neopazni. Uporaben je za grafike, avdio, video in slike, pri čemer odstranitev nekaterih bitov praktično nima opaznega učinka na predstavitev vsebine.
Huffmanov algoritem stiskanja
Ta postopek se lahko uporabi za "zmanjšanje" ali šifriranje. Temelji na dodelitvi kod različnih dolžin bitov, ki ustrezajo vsakemu ponavljajočemu se znaku, bolj kot so takšna ponovitve, višja je stopnja stiskanja. Za obnovitev izvorne datoteke morate poznati dodeljeno kodo in njeno dolžino v bitih. Podobno se aplikacija uporablja za šifriranje datotek. Postopek za ustvarjanje algoritmov za stiskanje podatkov:
Izračunajte, kolikokrat se vsak znak ponovi v datoteki za "zmanjšanje".
Ustvarite povezan seznam z informacijami o simbolih in frekvencah.
Opravi razvrščanje seznama od najmanjšega do največjega, odvisno od frekvence.
Pretvorite vsak element na seznamu v drevo.
Združite drevesa v eno, prva dva tvorita novo.
Doda frekvence za vsako vejo novemu drevesnemu elementu.
Vstavite novo na želeno mesto na seznamu glede na količino prejetih frekvenc.
Dodelite novo binarno kodo za vsak znak. Če je vzeta ničelna veja, se kodi doda nič in če se doda prva veja, se enota doda.
Datoteka je kodiranaujemanje z novimi kodami.
Na primer, značilnosti kompresijskih algoritmov za kratko besedilo: "ata la jaca a la estaca"
Preštejte, kolikokrat se vsak znak prikaže in sestavite povezan seznam: " ,
Vrstni red po frekvenci od najnižje do višje: e
,
,
), j
, s
, c
, l
, t
, , a
Kot lahko vidite, je korensko vozlišče drevesa ustvarjeno, potem so kode dodeljene.
In preostane samo pakiranje bitov v skupine po osem, to je bajtov:
01110010
11010101
11111011
00010010
11010101
11110111
)
0xd5
0xFB
0x12
0xd5
0xF7
91) 0xB9
0x80
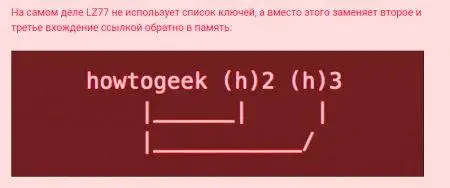
Vseh osem bajtov in izvorno besedilo je bilo 23. "Howtogeek". Če jo ponovite trikrat, ga spremenite na naslednji način.
Potem, ko želi prebrati besedilo nazaj, bo vsak primer (h) zamenjal z "howtogeek" in se vrnil na prvotno frazo. Prikazuje algoritem za stiskanje podatkov brez izgube, ker so vhodni podatki enaki kot podatki, ki jih prejmete.
To je odličen primer, ko je večina besedila stisnjena z nekaj znaki. Na primer, beseda "to" bo kratka, tudi če se pojavi v besedah "to", "njihovo" in "to". S ponavljajočimi se besedami lahko dobite ogromne razmerje stiskanja.Na primer, besedilo z besedo "howtogeek", ki se ponovi 100-krat v velikosti treh kilobajtov, s stiskanjem bo trajalo le 158 bajtov, to je s 95-odstotnim "zmanjšanjem".
To je seveda precej skrajni primer, vendar jasno kaže lastnosti kompresijskih algoritmov. Na splošno je 30-40% besedilne oblike ZIP. Algoritem LZ77 velja za vse binarne podatke in ne le za besedilo, čeprav je slednje lažje stisniti s ponavljajočimi se besedami.
Pretvorba diskretne kosinusne slike
Stiskanje videa in zvoka deluje povsem drugače. Za razliko od besedila, ki izvaja algoritme stiskanja brez izgube in podatki ne bodo izgubljeni, se slike "zmanjšajo" z izgubami, in več%, več izgub. To vodi do strašnih pogledov datotek JPEG, ki so jih ljudje večkrat prenesli, izmenjali in naredili posnetke zaslona. Večina slik, fotografij in drugih shrani seznam številk, od katerih vsaka predstavlja eno slikovno piko. JPEG jih shrani z algoritmom stiskanja slik, imenovanim diskretna kosinusna transformacija. Predstavlja niz sinusoidnih valov, ki so sestavljeni iz različne intenzivnosti. Ta metoda uporablja 64 različnih enačb, nato Huffmanovo kodiranje, da dodatno zmanjša velikost datoteke. Podoben algoritem za stiskanje slik daje izjemno visoko stopnjo stiskanja in ga zmanjšuje od nekaj megabajtov do več kilobajtov, odvisno od zahtevane kakovosti. Večina fotografij je stisnjenih, da prihranite čas prenosa, zlasti za mobilne uporabnikeslab prenos podatkov. Video deluje nekoliko drugače kot slika. Običajno algoritmi za stiskanje grafičnih informacij uporabljajo tako imenovane "medframečne kompresije", ki izračunajo spremembe med vsakim okvirjem in jih shranijo. Na primer, če obstaja relativno statična slika, ki traja nekaj sekund videoposnetka, se bo "zmanjšala" na eno. Interkom kompresija zagotavlja digitalno televizijo in spletno video. Brez tega je video tehtal več sto gigabajtov, kar je več kot povprečni trdi disk leta 2005. Stiskanje zvoka deluje zelo podobno kot stiskanje besedila in slik. Če JPEG izbriše podrobnosti slike, ki je nevidna za človeško oko, stiskanje zvoka enako velja za zvoke. MP3 uporablja bitno hitrost, ki sega od spodnjih 48 in 96 kbit /s (spodnja meja) do 128 in 240 kbps (dokaj dobra) do 320 kb /s (visokokakovosten zvok), razlika pa lahko slišite le pri zelo dobrih slušalkah. Obstajajo zvočni kodeki brez izgube, med katerimi je največji FLAC in uporablja kodiranje LZ77 za prenos zvoka brez izgub.
Formati za dekompresijo besedila
Razpon knjižnic za besedilo je v glavnem sestavljen iz algoritma za stiskanje podatkov brez izgub, razen v skrajnih primerih za podatke s plavajočo vejico. Večina kodekov kompresorjev vključuje "zmanjšanje" kodiranja LZ77 Huffman in Arithmetic. Uporabljajo se po drugih orodjih za stiskanje še nekaj odstotnih točk stiskanja.
Zaženi vrednosti, kodirane kot znak, ki mu sledi dolžina teka. Izhod lahko pravilno obnovitepretok Če je dolžina serije